
Hệ thống showroom
01 KCCSHOP – HÀ NỘI
Địa chỉ: Số 1 phố Yên Lãng, Trung Liệt, Đống Đa, Hà Nội
Kinh Doanh : 0912.074.444
Kinh Doanh : 05233.12345
Kinh Doanh : 05631.12345
Kinh Doanh : 05628.12345
Bảo Hành : 0888.129.444
Khiếu Nại Dịch Vụ : 0886.886.365
Open : 08H30 - 21H00 hàng ngày
02 KCCSHOP – HỒ CHÍ MINH
Địa chỉ: 8B Lý Thường Kiệt, Phường 12, Quận 5, TP.HCM
Kinh Doanh : 0966.666.308
Kinh Doanh : 05833.12345
Bảo Hành : 0966.666.308
Khiếu Nại Dịch Vụ : 0886.886.365
Open : 08H30 - 21H hàng ngày














AMD MI300X vượt trội hơn Nvidia H100 với hiệu suất tăng 30% và bộ chồng phần mềm tối ưu
04-01-2024, 8:47 pm
AMD còn tiến một bước nữa bằng cách tạo các tình huống kiểm thử tương tự như Nvidia đã thực hiện với TensorRT-LLM và đồng thời tính đến độ trễ, điều này thường xuyên xuất hiện trong các công việc máy chủ.

Cả AMD lẫn Nvidia đều không có ý định rút lui khỏi cuộc tranh cãi xoay quanh sự khác biệt về hiệu suất giữa các GPU Instinct MI300X và H100 (Hopper). Tuy nhiên, AMD đã đưa ra một số điểm mạnh khi so sánh FP16 sử dụng vLLM, một lựa chọn phổ biến hơn so với FP8, chỉ hoạt động với TensorRT-LLM.
Đội đỏ công bố card đồ họa MI300X vào đầu tháng 12 này, tuyên bố có sự vượt trội lên đến 1.6X so với H100 của Nvidia. Hai ngày trước đó, Nvidia đã đáp trả bằng cách nói rằng AMD không sử dụng các tối ưu hóa của mình khi so sánh H100 với TensorRT-LLM. Phản hồi này liên quan đến một H100 duy nhất so với tám GPU H100 chạy mô hình Llama 2 70B chat.
Trong phản hồi mới nhất này, AMD nói rằng Nvidia đã sử dụng một tập hợp chọn lọc của các công việc tính toán. Họ tiếp tục chỉ ra rằng Nvidia đã đánh giá chúng bằng cách sử dụng TensorRT-LLM nội bộ trên H100 thay vì vLLM, một phương pháp mã nguồn mở và được sử dụng rộng rãi. Hơn nữa, Nvidia đã sử dụng kiểu dữ liệu hiệu suất FP16 của vLLM trên AMD khi so sánh kết quả với DGX-H100, sử dụng TensorRT-LLM với kiểu dữ liệu FP8 để hiển thị những kết quả đặt ra là nhiễu loạn. AMD nhấn mạnh rằng trong thử nghiệm của mình, họ đã sử dụng vLLM với bộ dữ liệu FP16 do sự phổ biến của nó, và vLLM không hỗ trợ FP8.
Cũng có điểm cho rằng các máy chủ sẽ có độ trễ, nhưng thay vì tính đến điều đó, Nvidia đã hiển thị hiệu suất thông lượng của mình, không mô phỏng tình huống thực tế theo AMD.
Kết quả Thử Nghiệm Cập Nhật của AMD với Nhiều Tối Ưu Hóa Hơn và Tính Đến Độ Trễ Theo Phương Pháp Kiểm Thử của Nvidia
AMD đã thực hiện ba chuỗi thử nghiệm hiệu suất bằng cách sử dụng TensorRT-LLM của Nvidia, trong đó kết quả đáng chú ý nhất là việc đo lường kết quả độ trễ giữa MI300X và vLLM sử dụng bộ dữ liệu FP16 so với H100 với TensorRT-LLM. Tuy nhiên, thử nghiệm đầu tiên liên quan đến việc so sánh giữa hai máy sử dụng vLLM, vì vậy là FP16, và trong thử nghiệm thứ hai, AMD đã so sánh hiệu suất của MI300X với vLLM trong khi so sánh với TensorRT-LLM.
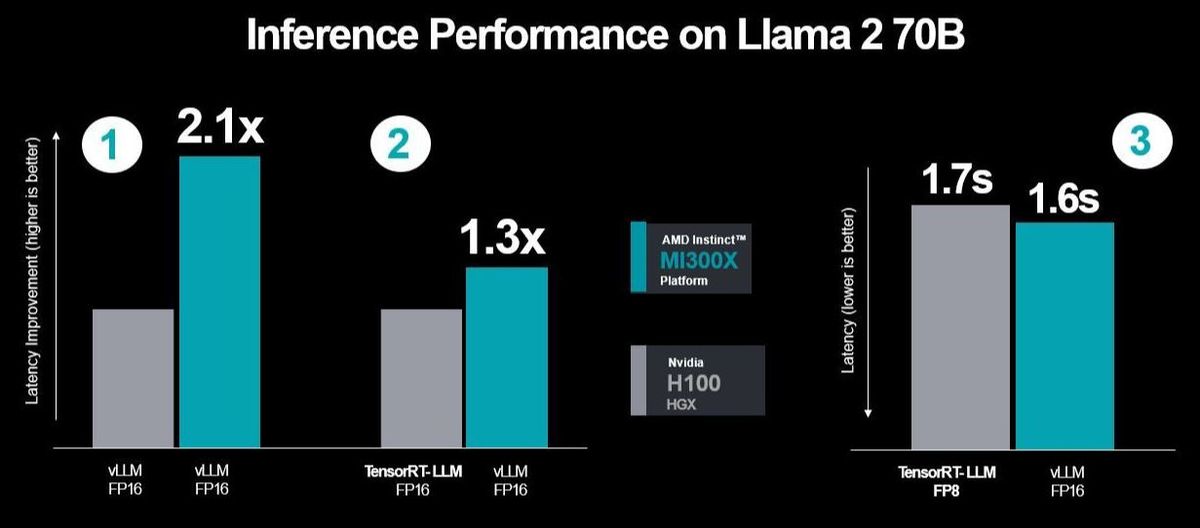
Vậy là, AMD đã sử dụng cùng một kịch bản kiểm thử được chọn lựa mà Nvidia đã sử dụng trong các kịch bản thử nghiệm thứ hai và thứ ba của mình, thể hiện hiệu suất cao hơn và độ trễ giảm đi. Công ty đã thêm vào đó nhiều tối ưu hóa so với H100 khi chạy vLLM trên cả hai máy, mang lại một sự tăng cường hiệu suất lên đến 2.1 lần.
Bây giờ là lúc Nvidia phải đánh giá xem họ muốn phản ứng như thế nào. Tuy nhiên, họ cũng cần nhận thức rằng điều này sẽ đòi hỏi ngành công nghiệp từ bỏ FP16 với hệ thống đóng của TensorRT-LLM để sử dụng FP8, tức là từ bỏ vLLM một cách hoàn toàn. Khi nói về giá trị cao cấp của Nvidia, một người dùng Reddit từng nói, "TensorRT-LLM miễn phí giống như những thứ đi kèm miễn phí với một chiếc Rolls Royce.
Bài viết liên quan











Những khách hàng luôn đồng hành cùng kccshop














Thêm sản phẩm vào giỏ hàng thành công!
Nhận tin khuyến mãi
Bạn vui lòng để lại Email để nhận thông tin
khuyến mãi từ Kccshop
khuyến mãi từ Kccshop
Chính sách chung
Chính sách bảo hành
Chính sách đổi trả
Chính sách vận chuyển
Chính sách bảo mật thông tin
Thông tin khác
Fan Page KCCSHOP
SĐT: 0912.074.444 (8:00 - 21:00)
Email: khanhchungcomputer@gmail.com
Phương thức thanh toán
