
Hệ thống showroom
01 KCCSHOP – HÀ NỘI
Địa chỉ: Số 1 phố Yên Lãng, Trung Liệt, Đống Đa, Hà Nội
Kinh Doanh: 0912.074.444
Bảo Hành: 0888.129.444
Khiếu Nại Dịch Vụ: 0886.886.365
Open: 08H30 - 21H00 hàng ngày
02 KCCSHOP – HỒ CHÍ MINH
Địa chỉ: 8B Lý Thường Kiệt, Phường 12, Quận 5, TP.HCM
Kinh Doanh: 0966.666.308
Bảo Hành: 0566.578.555
Khiếu Nại Dịch Vụ: 0886.886.365
Open: 08H30 - 21H hàng ngày














Nvidia Hopper H200 phá vỡ kỷ lục của bài kiểm tra MLPerf với TensorRT - chưa có đề xuất từ Blackwell
07-04-2024, 9:35 pm
Nvidia đã vượt qua kỷ lục MLPerf trước đó của mình với phần mềm và phần cứng được tối ưu mới.

Nvidia thông báo rằng GPU AI mới Hopper H200 kết hợp với TensorRT LLM tăng hiệu suất đã phá vỡ kỷ lục trong các thử nghiệm hiệu suất MLPerf mới nhất. Sự kết hợp này đã tăng hiệu suất của H200 lên đến 31,712 token mỗi giây trong bài kiểm tra Llama 2 70B của MLPerf, tăng 45% so với GPU Hopper thế hệ trước H100 của Nvidia.
Hopper H200 về cơ bản là cùng một vi mạch như H100, nhưng bộ nhớ đã được nâng cấp lên 24GB 12-Hi stacks của HBM3e. Điều này dẫn đến 141GB bộ nhớ cho mỗi GPU với băng thông 4.8 TB/s, trong khi H100 thường chỉ có 80GB mỗi GPU (94GB trên một số mô hình cụ thể) với tối đa 3 TB/s băng thông.
Kỷ lục này không nghi ngờ sẽ được phá vỡ vào cuối năm nay hoặc đầu năm sau, khi các GPU Blackwell B200 sắp tới ra mắt. Có thể Nvidia đã có Blackwell trong nhà và đang được thử nghiệm, nhưng nó chưa được công bố công khai. Tuy nhiên, Nvidia tuyên bố hiệu suất lên đến 4 lần so với H100 cho các tải công việc huấn luyện.
Nvidia là nhà sản xuất phần cứng AI duy nhất trên thị trường đã công bố kết quả đầy đủ từ khi các bài kiểm tra của MLPerf trở nên có sẵn từ cuối năm 2020. Phiên bản mới nhất của bài kiểm tra MLPerf sử dụng bài kiểm tra mới Llama 2 70B, là một mô hình ngôn ngữ tiên tiến sử dụng 70 tỷ tham số. Llama 2 lớn hơn hơn 10 lần so với mô hình ngôn ngữ GPT-J đã được sử dụng trước đây trong các bài kiểm tra của MLPerf.
Các bài kiểm tra của MLPerf là một bộ bài kiểm tra được phát triển bởi ML Commons nhằm cung cấp các đánh giá không thiên vị về hiệu suất huấn luyện và suy luận cho phần mềm, phần cứng và dịch vụ. Toàn bộ bộ bài kiểm tra bao gồm nhiều mẫu thiết kế mạng nơ-ron AI, bao gồm GPT-3, Stable Diffusion V2 và DLRM-DCNv2 để kể một số.
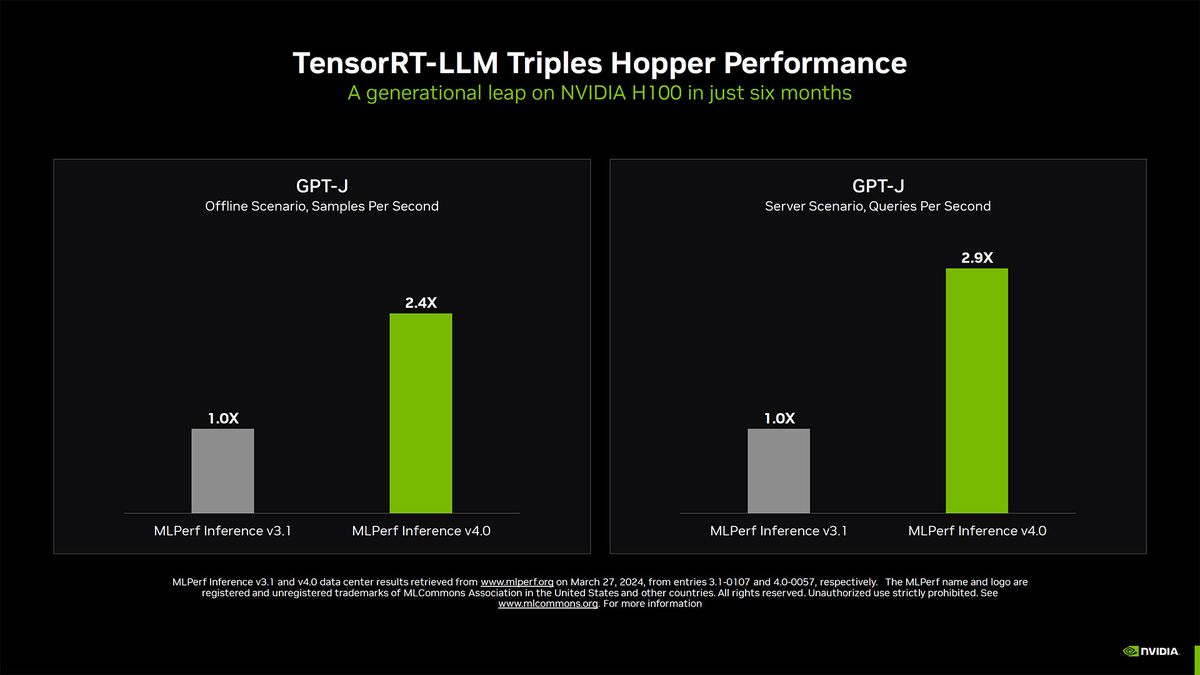
Nvidia cũng đã nhấn mạnh được mức độ cải thiện hiệu suất của GPU H100 với phần mềm TensorRT của mình - một bộ công cụ mã nguồn mở để giúp tăng tốc độ xử lý hiệu quả của các GPU của hãng. TensorRT bao gồm một số yếu tố, bao gồm song song tensor và batching trong chuyến bay. Song song tensor sử dụng các ma trận trọng số cá nhân để chạy một mô hình AI một cách hiệu quả trên nhiều GPU và máy chủ. Batching trong chuyến bay loại bỏ các chuỗi các yêu cầu batch đã hoàn thành và bắt đầu thực hiện các yêu cầu mới trong khi các yêu cầu khác vẫn đang trong chuyến bay.
Các cải tiến TensorRT khi áp dụng vào bài kiểm tra MLPerf GPT-J đã dẫn đến sự cải thiện 3 lần trong hiệu suất trong vòng sáu tháng qua - cho cùng phần cứng.
Nvidia cũng đã nhấn mạnh hiệu suất của mình trong MLPerf Llama 2 70B so với giải pháp NPU Gaudi2 của Intel. Theo biểu đồ của Nvidia, H200 đã đạt được kỷ lục thế giới 31,712 điểm trong chế độ máy chủ với các cải tiến TensorRT-LLM. Trong chế độ offline, chip đạt được 29,526 điểm. Các điểm số mới của H200 nhanh khoảng 45% so với những gì H100 có thể đạt được, chủ yếu nhờ vào băng thông và dung lượng bộ nhớ nhiều hơn. Trong cùng bài kiểm tra, sử dụng TensorRT cũng như, H100 đạt được 21,806 và 20,556 điểm trong chế độ máy chủ và offline, tương ứng. So với đó, kết quả của Gaudi2 của Intel chỉ là 6,287 và 8,035 điểm trong chế độ máy chủ và offline.
Ngoài TensorRT, Nvidia đã tích hợp vào các GPU của mình một số tối ưu hóa khác. Sự thưa thớt có cấu trúc được cho là tăng tốc độ 33% trong suy luận với Llama 2 bằng cách giảm thiểu các phép tính trên GPU. Tỉa cây là một tối ưu hóa khác giúp đơn giản hóa một mô hình AI hoặc LLM để tăng suất suy luận. DeepCache giảm bớt phép tính cần thiết cho suy luận với các mô hình Stable Diffusion XL, tăng tốc hiệu suất lên đến 74%.
Bài viết liên quan




Màn hình HP Omen Transcend 32 OLED có cổng DisplayPort 2.1 chậm hơn HDMI 2.1
24-03-2024, 3:02 pm


AMD sẽ ra mắt công nghệ mở rộng quy mô mới dựa trên "trí tuệ nhân tạo"
20-03-2024, 11:17 pm

Bao bì của Intel Core i9-14900KS được tiết lộ khi nó được phát hiện tại Việt Nam.
17-03-2024, 10:02 pm




Những khách hàng luôn đồng hành cùng kccshop














Thêm sản phẩm vào giỏ hàng thành công!
Nhận tin khuyến mãi
Bạn vui lòng để lại Email để nhận thông tin
khuyến mãi từ Kccshop
khuyến mãi từ Kccshop
Chính sách chung
Chính sách bảo hành
Chính sách đổi trả
Chính sách vận chuyển
Chính sách bảo mật thông tin
Thông tin khác
Fan Page KCCSHOP
SĐT: 0912.074.444 (8:00 - 21:00)
Email: khanhchungcomputer@gmail.com
Phương thức thanh toán
